
附录A: 延伸阅读
A.1 北斗信号解析过程
北斗信号解析过程在RTKLIB中主要在rtcm3.c和rinex.c中,主要关注引用obs2code和code2idx函数的地方,其他星座信号解析方法相同,具体的:
/* 1. 实时解析:save_msm_obs (rtcm3.c) */
/* signal to rinex obs type */
code[i]=obs2code(sig[i]);
idx[i]=code2idx(sys,code[i]);
…
/* get signal index */
sigindex(sys,code,h->nsig,rtcm->opt,idx);
/* 2. 后处理解析:readrnxobsb/set_index (rinex.c) */
/* set signal index */
for (i=n=0;*tobs[i];i++,n++) {
ind->code[i]=obs2code(tobs[i]+1);
ind->type[i]=(p=strchr(obscodes,tobs[i][0]))?(int)(p-obscodes):0;
ind->idx[i]=code2idx(sys,ind->code[i]);
ind->pri[i]=getcodepri(sys,ind->code[i],opt);
ind->pos[i]=-1;
}以下是解析流程的概述:
1. 设置索引
初始化信号标识的索引,将频率带(如B1-2、B2a、B3)及其调制类型(I、Q、I+Q、数据、导频等)映射到内部数据结构。
2. obs2code
static char *obscodes[]={ /* observation code strings */
"" ,"1C","1P","1W","1Y", "1M","1N","1S","1L","1E", /* 0- 9 */
"1A","1B","1X","1Z","2C", "2D","2S","2L","2X","2P", /* 10-19 */
"2W","2Y","2M","2N","5I", "5Q","5X","7I","7Q","7X", /* 20-29 */
"6A","6B","6C","6X","6Z", "6S","6L","8L","8Q","8X", /* 30-39 */
"2I","2Q","6I","6Q","3I", "3Q","3X","1I","1Q","5A", /* 40-49 */
"5B","5C","9A","9B","9C", "9X","1D","5D","5P","5Z", /* 50-59 */
"6E","7D","7P","7Z","8D", "8P","4A","4B","4X","" /* 60-69 */
};此函数将观测码标识(如"2I"、"QX")转换为obscodes数组中的索引(对应RTKLIB中的CODE_*常量)。例如,B1-2/1561.098的"2I"可能映射为CODE_L1I,表示L1频率的同相分量。其中obscodes数组如上所示。
3. code2idx
确定每个频率数据的存储位置。例如,根据优先级分配位置(如L1在0号位),确保观测数据一致性。其中调用的code2freq_BDS函数,从而最终决定了北斗频点的使用规则。
4. getcodepri
static char codepris[7][MAXFREQ][16]={ /* code priority for each freq-index */
/* L1/E1/B1I L2/E5b/B2I L5/E5a/B2a E6/LEX/B3I E5(a+b)/B2(a+b) */
{"CPYWMNSL","CPYWMNDLSX","IQX" ,"" ,"" }, /* GPS */
{"CPABX" ,"CPABX" ,"IQX" ,"" ,"" }, /* GLO */
{"CABXZ" ,"XIQ" ,"XIQ" ,"ABCXZ" ,"IQX" }, /* GAL */
{"CLSXZ" ,"LSX" ,"IQXDPZ" ,"LSXEZ" ,"" }, /* QZS */
{"C" ,"IQX" ,"" ,"" ,"" }, /* SBS */
{"IQXDPAN" ,"IQXDPZ" ,"DPX" ,"IQXA" ,"DPX" }, /* BDS */
{"ABCX" ,"ABCX" ,"" ,"" ,"" } /* IRN */
};评估同一频率下不同码(如I、Q、I+Q)的优先级,使用rtkcmn.c中的codepris数组。
表A-1 RINEX 3.04 北斗观测码
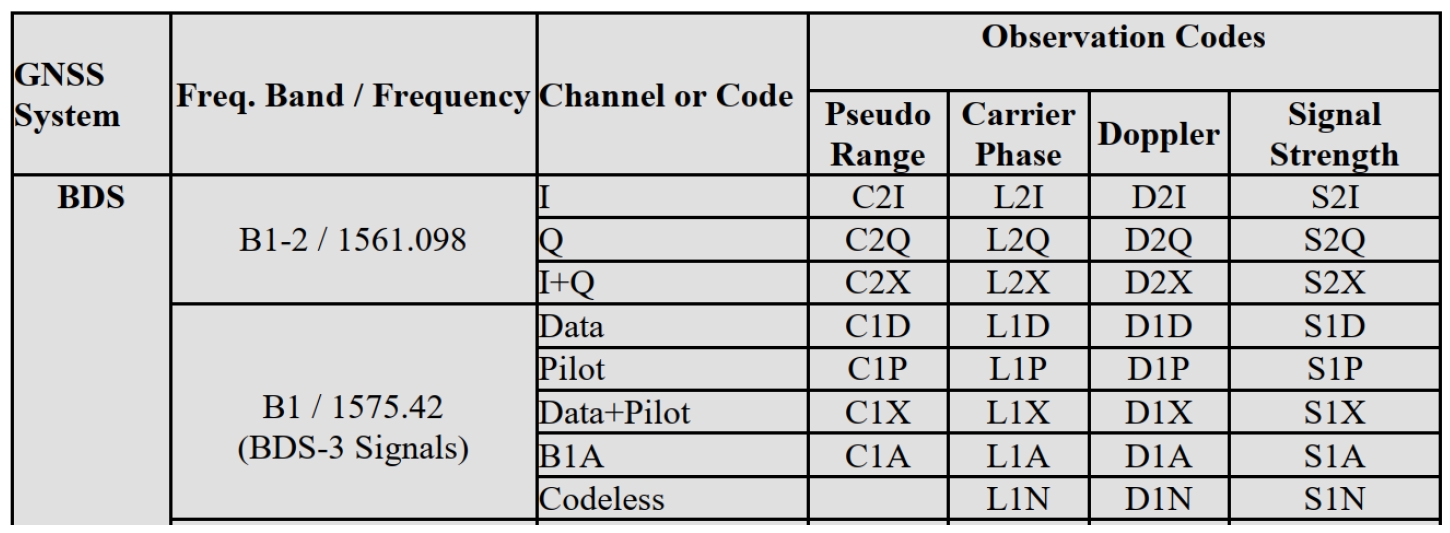
基于预定义优先级选择最高优先级的码,例如I优于I+Q。
A.2 自适应MASK阈值
可以将mask的判断逻辑放到了rescode的内部for循环中,也可以在外面构建,然后循环执行rescode函数,然后传入拷贝的opt变量,这样代码会更清晰一些。
A.3 MGEX-AGNSS服务
服务网址:mgex.igs-ip.net GNSS Streaming Server
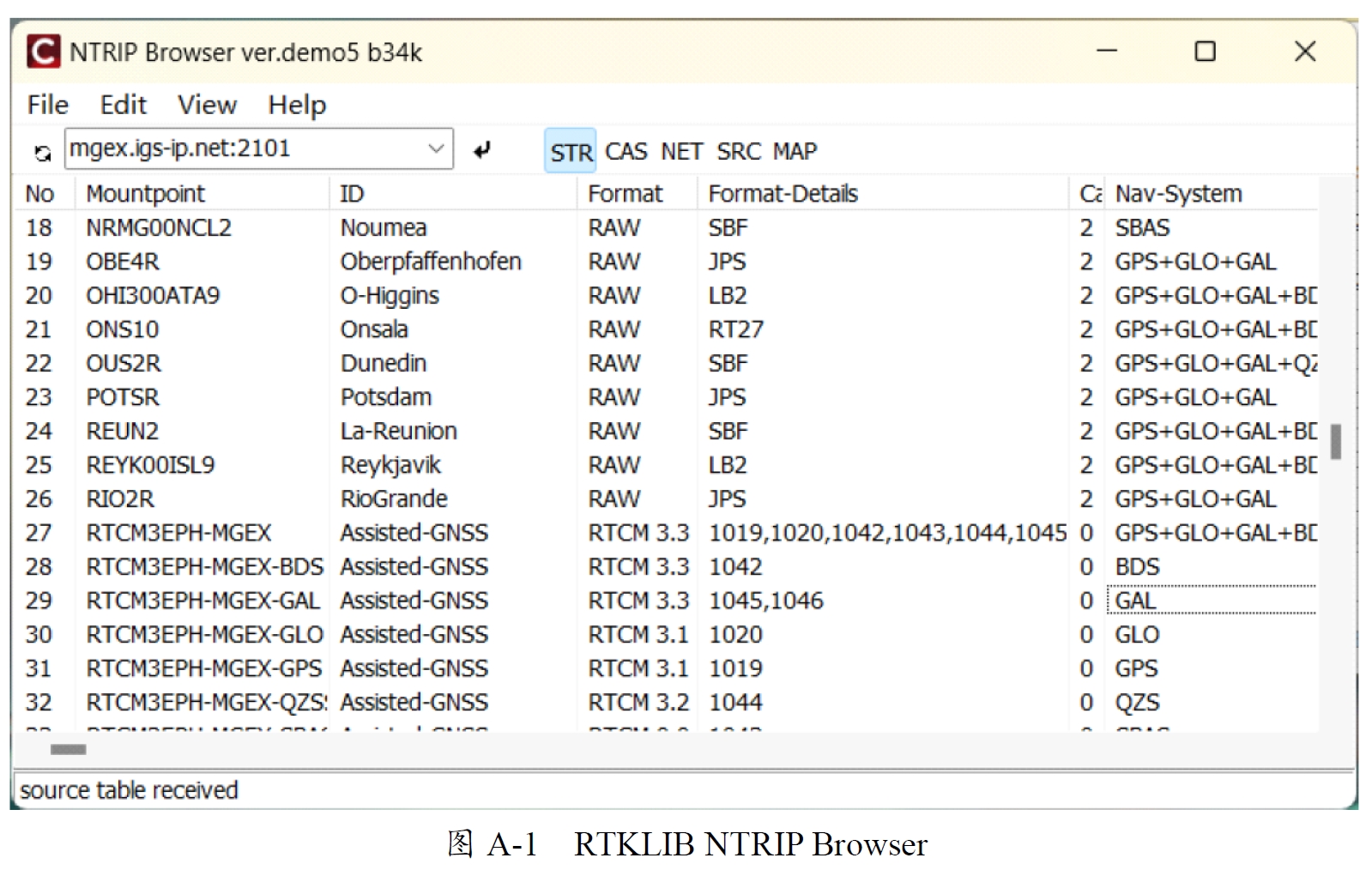
图A-1 RTKLIB NTRIP Browser
使用RTKLIB的NTRIP服务工具连接星历AGNSS服务,选择RTCM3EPH-MGEX挂载点。可以直接挂着该服务让它每天源源不断接收RTCM格式的星历数据即可,由于并不是流媒体格式,因此并不会占据很多内存。长期后台录制主要是为了避免有时候做实验忘记记录星历了。
后面可以使用RTKCONV将RTCM星历数据转换为RINEX格式,并用在算法优化上。
A.4 批处理程序
点击查看代码
import os
import subprocess
import time
################## USER INPUT BEGIN #######################
"""
Referring: https://rtklibexplorer.wordpress.com/2022/01/05/batch-processing-rtklib-solutions-with-rnx2rtkp-and-python/
Note :
该脚本为后处理批处理脚本,能同时跑不同配置的多组数组,具体的:
会运行CONF_PATH配置文件夹下所有的配置,以及DATA_PATH文件夹下所有的RINEX数据,
结果会以配置文件的名称(CONF_PATH)作为分类文件夹,存储多组结果数据(DATA_PATH内所有RINEX文件)。
TBD :
1)需要解决DATA_DIR下属直接包含RINEX文件但不能处理的BUG
"""
BIN_DIR = "../app/rnx2rtkp/msc/Release" # 可执行文件所在目录
DATA_DIR = "../data" # 输入文件目录。输入文件要求在data目录内部,且名称必须为rover.obs、base.obs、rover.nav
CONF_DIR = "../app/rnx2rtkp/conf" # 配置文件夹。配置文件必须以.conf结尾
OUTS_DIR = "./output" # 输出文件
TRACE_LEVEL = 0 # trace等级
################## USER INPUT END #######################
# set maximum number of simultaneous occurences of rnx2rtkp to run
max_windows = 14
poll_list = [None] * max_windows
slash_type = "\\" if os.name == "nt" else "/"
def ExecPostProc(bin, src, out, cfg):
# create command to run solution
if os.name == "nt":
rtk_cmd = r'%s\rnx2rtkp.exe -ti 1.0 -x %d -y 0 -k %s -o %s.pos %s\rover.obs %s\base.obs %s\rover.nav' % \
(bin, TRACE_LEVEL, cfg, out, src, src, src)
else:
rtk_cmd = r'%s/rnx2rtkp -x %d -y 0 -k %s -o %s.pos %s/rover.obs %s/base.obs %s/rover.nav' % \
(bin, TRACE_LEVEL, cfg, out, src, src, src)
# run command
return subprocess.Popen(rtk_cmd, shell=True)
def GetConfigs(cfg_path):
cfgs = []
paths = os.walk(cfg_path)
for _, _, files in paths:
for f in files:
if ".conf" in f:
cfgs.append(f)
return cfgs
def GenPostProcParas(data_path):
input_dirs = []
output_files = []
paths = os.walk(data_path)
for path, dir_lst, _ in paths:
for dir_name in dir_lst:
if (os.path.exists(os.path.join(path, dir_name)+"/rover.obs")):
target_dir = os.path.join(path, dir_name)
target_arr = target_dir.split(slash_type+"data"+slash_type)[-1].split(slash_type)
pos_name = "_".join(target_arr)
input_dirs.append(target_dir)
output_files.append(pos_name)
return input_dirs, output_files
def GetPollStat(polls):
stats = []
for p in polls:
if p is not None and (p.poll() is None):
stats.append(1)
else:
stats.append(0)
return stats
def CheckIsFinished(polls):
is_finished = True
for p in polls:
if p is not None and (p.poll() is None):
is_finished = False
return is_finished
# 删除output中所有的event文件
def DeleteFilesWithName(folder_path, keyword):
for root, _, files in os.walk(folder_path):
for file in files:
if keyword in file:
file_path = os.path.join(root, file)
os.remove(file_path)
if __name__ == "__main__":
start_time = time.time()
cur_path = os.path.abspath(os.path.dirname(__file__))+"/"
bin_path = os.path.abspath(cur_path + BIN_DIR)
data_path = os.path.abspath(cur_path + DATA_DIR)
conf_path = os.path.abspath(cur_path + CONF_DIR)
output_path = os.path.abspath(cur_path + OUTS_DIR)
input_paths, output_files = GenPostProcParas(data_path)
cfgs = GetConfigs(conf_path)
# loop through date folders
ntasks = 0
for src, out in zip(input_paths, output_files):
for cfg in cfgs:
is_idle = 0
# if max windows open, wait for one to close
while is_idle == 0:
for j, p in enumerate(poll_list):
if p is None:
is_idle = 1
elif p.poll() is not None:
poll_list[j] = None
is_idle = 1
time.sleep(1) # wait here for existing window to close
for j, p in enumerate(poll_list):
if p is None:
is_idle = 1
out_path = os.path.join(output_path, cfg+slash_type+out)
poll_list[j] = ExecPostProc(bin_path, src, out_path, conf_path+slash_type+cfg)
ntasks += 1
print('Process: {:0>3d}/{:0>3d} '.format(ntasks, len(output_files)*len(cfgs)))
break
# Wait for all solutions to finish
print('Waiting for solutions to complete ...')
poll_sum = 0
while CheckIsFinished(poll_list) == False:
poll_stat = GetPollStat(poll_list)
if (poll_sum != sum(poll_stat)):
poll_sum = sum(poll_stat)
print('Poll busy status({:0>3d}/{:0>3d}): '.format(poll_sum, max_windows), poll_stat)
time.sleep(1)
end_time = time.time()
DeleteFilesWithName(output_path, "_events.pos")
print('Batch processing completed in {0:.2f}s'.format(end_time-start_time))这是一个 Python 脚本,用于批量运行 RTKLIB 的 rnx2rtkp 程序,处理 RINEX 格式的 GNSS 数据,可以结合多个配置文件(.conf),生成定位结果(.pos 文件)。
1. 核心功能
- 输入:
- 可执行文件目录(
BIN_DIR):rnx2rtkp程序路径。 - 数据目录(
DATA_DIR):包含 RINEX 文件的子目录。 - 配置目录(
CONF_DIR):.conf配置文件。 - 输出目录(
OUTS_DIR):结果按配置文件名分类存储。
- 可执行文件目录(
- 输出:结果存储在
OUTS_DIR/<配置文件名>/<数据子目录>.pos。
2. 特点
- 支持 Windows/Linux(动态路径分隔符)。
- 限制并行进程数以优化性能(
max_windows)。
A.5 C语言中的atan和atan2
C语言的<math.h>或C++的<cmath>中有两个反正切函数:atan和atan2,返回值是弧度,需乘以180/PI转为角度。该部分内容参考资料[14]。
atan(double x)
- 输入:斜率。
- 输出:
-90°到90°,只覆盖一、四象限。 - 局限:不能区分不同象限的相同斜率。
- 示例:
atan(1.0)*180/PI→45°,atan(-1.0)*180/PI→-45°。
atan2(double y, double x)
- 输入:坐标
(x, y)。 - 输出:
-180°到180°,覆盖所有象限,表示与x轴正方向的夹角。 - 示例:
atan2(1.0, 1.0)*180/PI→45°(第一象限)。atan2(-1.0, -1.0)*180/PI→-135°(第三象限)。
- 输入:坐标
线段夹角
- 用
atan2(y2-y1, x2-x1)计算线段AB与x轴夹角。 - 示例:A(0.0,5.0), B(5.0,10.0),
atan2(10.0-5.0, 5.0-0.0)*180/PI→45°。
- 用
总结:atan2更实用,能处理所有象限,适合计算点或线段的角度。
A.6 C/N0、SNR与CNR
GNSS领域中常把C/N0称为“SNR”,主要是因为SNR是更广为人知的术语。但在技术上,C/N0是更准确的指标,反映了GNSS信号的载波功率与噪声密度关系。C/N0、SNR和CNR的定义、用途和表达方式有所不同。以下是它们的区别:
1. C/N0(Carrier-to-Noise Density Ratio,载波噪声密度比)
- 定义:C/N0是载波功率与单位带宽内噪声功率的比值,单位通常为dB-Hz。
- 公式:C/N0 = 10 * log10(Pc / N0),其中Pc是载波功率,N0是噪声功率谱密度。
- 典型值:在GNSS中,C/N0通常在30 dB-Hz到50 dB-Hz之间,值越高表示信号质量越好。
2. SNR(Signal-to-Noise Ratio,信噪比)
- 定义:SNR是信号功率与噪声功率的比值,单位通常为dB。
- 公式:SNR = 10 * log10(Ps / Pn),其中Ps是信号功率,Pn是总噪声功率。
- 典型值:GNSS接收机的SNR值可能在10 dB到30 dB之间,具体取决于设备和环境。
3. CNR(Carrier-to-Noise Ratio,载噪比)
- 定义:CNR是载波功率与总噪声功率的比值,单位为dB。
- 公式:CNR = 10 * log10(Pc / Pn),其中Pc是载波功率,Pn是总噪声功率。
- 典型值:CNR值通常低于C/N0,具体数值取决于带宽和环境。
三者主要区别总结如下:
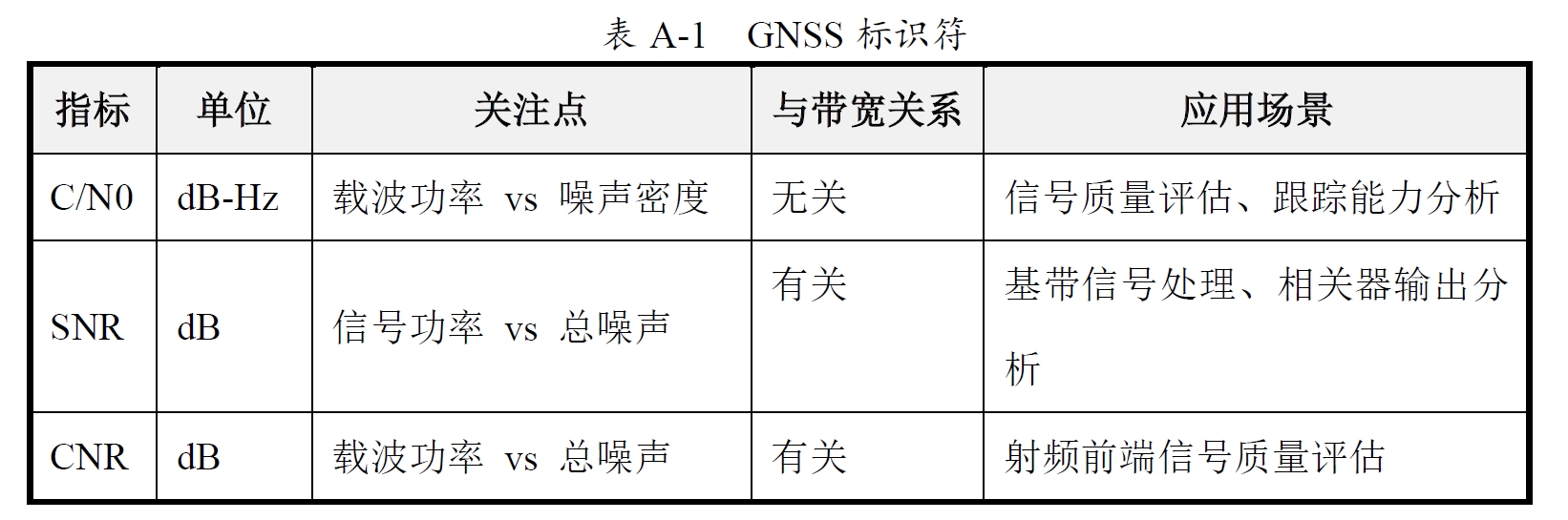
C/N0是GNSS中最常用的指标,用于判断信号是否足以被接收机捕获和跟踪,尤其在弱信号环境(如城市峡谷、室内)中非常关键。 SNR常用于接收机内部的信号处理分析,帮助优化算法或评估抗噪性能。 CNR多用于射频阶段,反映天线和前端硬件的性能。
A.7 Moving-Base模式和基线约束
moving-base模式相比于kinematic模式有以下主要区别[5](具体可以看手册和代码):
- 定位精度:每个历元基站的位置为其单点定位的位置
- 时间同步:对基站、移动站量测量的时间同步会有更严格的要求,最大的时间差小于1.05s,maxage的配置不起作用
- 极限约束:配置中可以增加基线约束,可以设置基线长度以及其标准差
- 滤波迭代:配置中可以增加卡尔曼滤波器的迭代次数
1. 为什么Moving-Base模式需要将Rec Dynamic设为OFF?
在Moving-Base模式下,初始测试结果显示固定解的比例较低(几乎无固定解)。经过分析发现,将Rec Dynamic设置为OFF可以改善性能。
Rec Dynamic的本质是在卡尔曼滤波中引入速度和加速度状态量。在Moving-Base模式下,基站位置每历元通过单点定位确定,导致加速度变化较大。然而,卡尔曼滤波的一步预测假设加速度保持不变,这会错误地滤除加速度的变化,影响定位精度,最终导致较差的结果。
2. 为什么动态基站下仍可使用Kinematic模式定位?
即使基站处于动态(移动)状态,Kinematic模式仍能有效定位。
差分定位的核心是求解基线向量,而非移动站的绝对位置。在载波相位双差方程中,未知量仅包括基线向量和模糊度。基站的移动(只要距离不太远,例如几公里内)对视线向量(Line of Sight)的计算影响较小。因此,即使基站位置存在一定偏差,只要偏差不显著,对基线向量的求解影响有限。
3. 为什么Kinematic模式结果优于Moving-Base模式?
测试中发现,Kinematic模式的定位效果优于Moving-Base模式。以下是初步分析(未经深入验证):
Moving-Base模式(Rec Dynamic = OFF):
卡尔曼滤波的一步预测将移动站位置设为单点定位结果。这种预测引入较大误差,影响滤波结果及模糊度固定,降低定位精度。Kinematic模式(Rec Dynamic = ON):
通过速度状态量进行位置一步预测,相较于单点定位,预测结果更准确,有助于提高滤波性能和模糊度固定的成功率。
4. 如何提升Moving-Base模式的性能?
以下是一些改进Moving-Base模式性能的初步想法(尚未实践):
优化卡尔曼滤波状态量:
将移动站的位置状态量改为基线向量,速度状态量改为基线速度,以更直接地反映基线变化,减少预测误差。替代卡尔曼滤波:
探索不依赖卡尔曼滤波的定位方法,减少滤波器对动态变化的限制,适应Moving-Base模式的特性。
A.8 GLONASS模糊度固定的算法优化
和其他导航系统不同,由于GLONASS 采用频分多址,因此各卫星的载波相位存在一定的频间差(inter-frequency bias),这个硬件偏差导致GLONASS卫星的整周模糊度固定会比其他系统更加困难。
通常来说,频间差和频率号成正比,同一颗卫星L1和L2的频间差基本一致。对于同一制造商的所有接收机,频间差特性保持一致。如果基站和移动站使用来自不同厂家的接收机,由于频间差即使双差后也无法抵消,因此需要对其进行处理。
在demo5版本的RTKLIB代码中,作者设置了四种GLONASS的模式[8]:
- off:如果 GLONASS AR 设置为 OFF,则 GLONASS 的伪距、载波相位只用于计算浮点解。如果基站和移动站使用了不同厂家的接收机,并且采用 GLONASS 整周模糊度固定情况很差,卫星足够的情况下,可以尝试该选项,不进行 GLONASS 的整周模糊度固定。不过如果在星况较差的情况下,这样会损失很多卫星。demo5 中不推荐使用这个设置。
- on:如果 GLONASS AR 设置为 on,那么 RTKLIB 对待 GLONASS 卫星和其他系统卫星一样,使用同样的方法去进行整周模糊度固定。如果基站和移动站接收机一致,或者移动站和基站的频间差一致,demo5 推荐使用这个设置。实际如果移动站和基站的频间差都非常小(毫米级或者亚毫米级),也可以先尝试这个配置,看看固定率和残差的情况,再决定是否需要更换设置。
- Fix-and-Hold:这是 Demo5 中增加的一个 GLONASS 设置选项,是其他系统 Fix-and-Hold 模式的延伸。在这个模式下,会等其他系统固定之后,才会进行 GLONASS 模糊度的固定。在这个模式下,每次会将 GLONASS 双差整周模糊度浮点解的小数部分认为是频间差,然后设置一个增益(0.01)将这部分误差存在 glo_icbias 中,让它慢慢收敛,在下一次更新时,会减掉这部分误差。具体可以参考资料 [9]。作者用数据证明了这个方法的有效性,并且推荐在使用不同接收机且频间差未知的情况下,使用该配置。不过个人感觉这个方法的理论支撑不太强。
- Auto-Cal:如果使用这个设置,会在卡尔曼滤波中增加额外的状态估计量来估计频间差。原版 RTKLIB 中也有这个选项,但是不能设置频间差的初始值和初始协方差阵。据 demo5 作者描述,如果频间差初始值和实际值相差太多,或者协方差阵不准的话,结果不会太理想,频间差估计不准确。demo5 在程序中增加了初始值和初始协方差的设置,并且在通过用零基线或者短基线的方法,基于论文 [10](该论文在标定频间差,和使用标定值作为先验值固定 GLONASS 整周模糊度方面起到了关键作用),标定出了不少接收机的频间差。这个方法是理论支撑最强的方法。
demo5中和GLONASS频间差相关的配置:
pos2-arthres2 = relative GLONASS hardware bias in meters per frequency slot
pos2-arthres3 = initial variance of GLONASS hardware bias states
pos2-arthres4 = process noise for GLONASS hardware bias statesdemo5作者标定出的各接收机频间差:
ComNav = 2.3 cm
Leica = 2.3 cm
Novatel = 2.3 cm
Septentrio = -0.3 cm
Spectra Physics = 0.0 cm
SwiftNav = 0.0 cm
Tersus = 0.0 cm
Topcon = 0.0 cm
Trimble = -0.7 cm
u-blox M8T = -3.2 cm
u-blox F9P = 0.0 cm博主认为,如果使用不同厂家的接收机,最好的方法还是用零基线的方法标定频间差,然后将这个先验值直接带入计算,从载波相位中把频间差扣除。 目前也看到GPS Solutions上的一篇论文[11],通过选两颗GLONASS参考星的方法,可以将由于时钟偏差引起的频间差消除。不过感觉作者也不确定频间差是否是由于时钟偏差引起,未曾尝试,不太确定这个方法是否靠谱,感兴趣的同学可以看看。
A.9 自适应Ratio
A.9.1 摘要
整数载波相位模糊度解算是快速、高精度全球导航卫星系统(GNSS)定位和应用的关键。除了整数估计外,模糊度解算过程还包括解的有效性检验。一种比较常见的检验方法是是比率值检验(ratio-test)。论文[12]的工作:
1. ratio-test
- 研究了ratio-test的特性及其背后的原理;
- 讨论了关于ratio-test的一些误解,特别是指出比率检验并不是用于检验整数最小二乘解正确性的测试;
- 表明了使用固定临界值的ratio-test存在不足之处。
2. fixed failure rate
- 推荐使用固定失败率(fixed failure rate)方法。这种方法是整数孔径估计(integer aperture estimation)理论的一部分,它能够确保失败率不超过用户定义的值;
- 通过一些实例,展示了固定失败率比率检验(fixed failure-rate ratio-test)的结果及其改进性能。
A.9.2 引言
全球导航卫星系统(GNSS)模糊度解算从概念上可以分为四个步骤:
- 获取浮点解。首先忽略模糊度的整数特性,进行标准的最小二乘估计。因此,可以得到所有参数(即模糊度、基线分量,以及其他参数,如大气延迟)的浮点解,以及它们的方差-协方差矩阵。
- 模糊度固定。对模糊度的浮点解进行整数约束,从而得到模糊度的整数解。整数取整(integer rounding)、整数引导(integer bootstrapping)和整数最小二乘法(ILS)是获得整数解的不同方法。其中整数最小二乘法是最佳的,因为它被证明能最大化正确整数估计的概率。与取整和引导不同,计算ILS解需要进行整数搜索(如可以通过LAMBDA方法完成)。
- 解的检验。已知的方法有比率检验(ratio-test)、距离检验(distance-test)和投影检验(projector-test)。
- 获取固定解。一旦接受整数解,第四步就是利用其他参数与模糊度的相关性,对所有其他参数的浮点解进行修正。因此,可以得到所谓的固定解(fixed solution)。如果在第三步中做出了正确的决策,固定解将具有与相位数据高精度相一致的精度。 本文重点讨论了其中的第三步,并特别研究了比率检验的特性及其应用。
A.9.3 图表
1. ratio-test的二维几何示意图
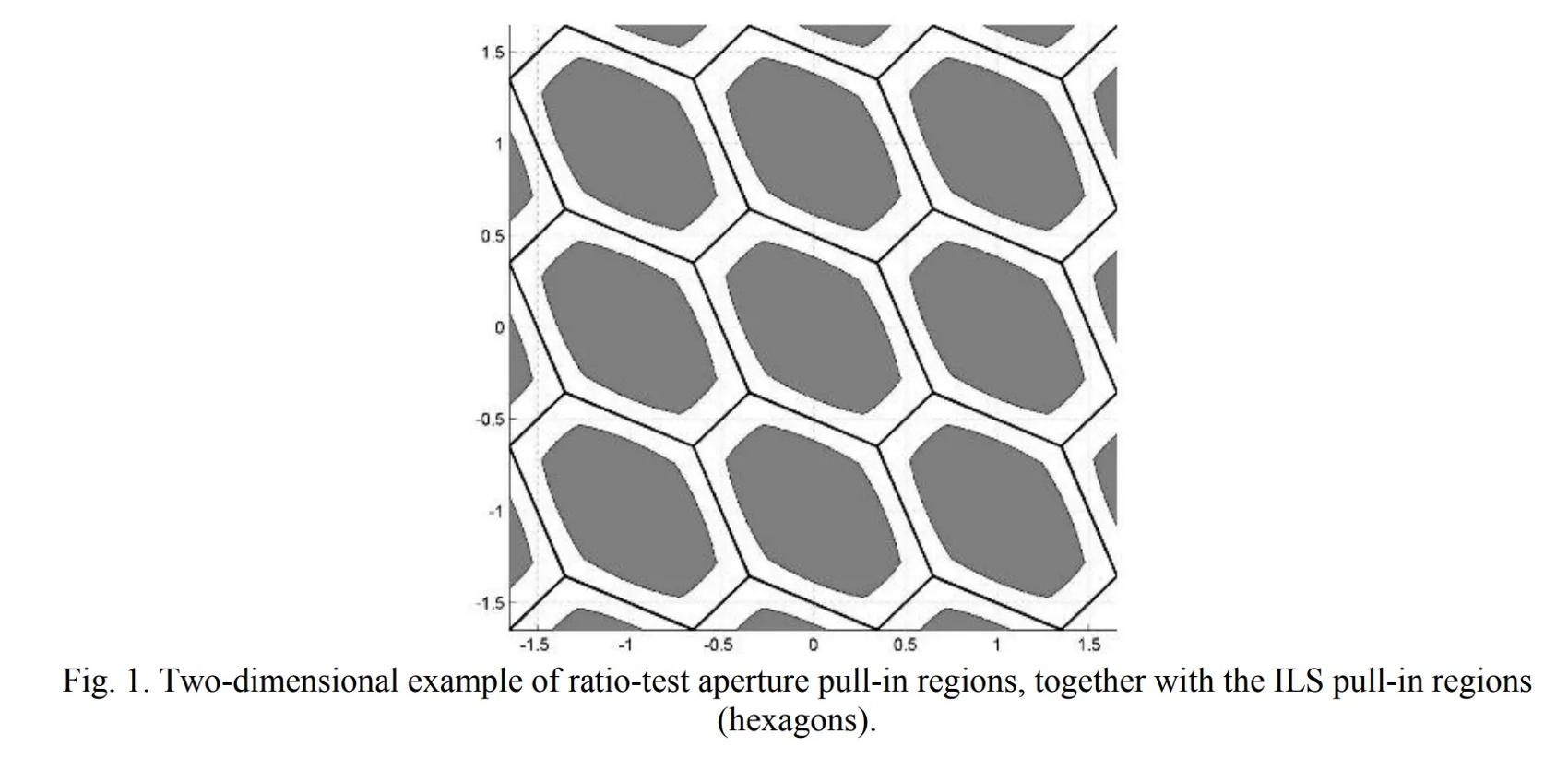
图A.9-1 ratio-test孔径拉入区域的二维示例,包含 ILS 拉入区域(六边形)
上图表示整数搜索的二维示意图,其中黑色区域代表距离整数置信度较高的区域,而白色刚好相反。
- 白色与黑色。ratio-test通过的时候即在黑色区域(Fix),不通过则在白色区域(Float)。
- 六边形。六边形可能是椭圆的近似体现,其形状由浮点解的方差矩阵决定。
- 平移不变。这里的出现了多个相同的六边形,它代表了将整个求解区域进行整数单位的平移,其形状特征没有变化。
2. 成功率与失败率
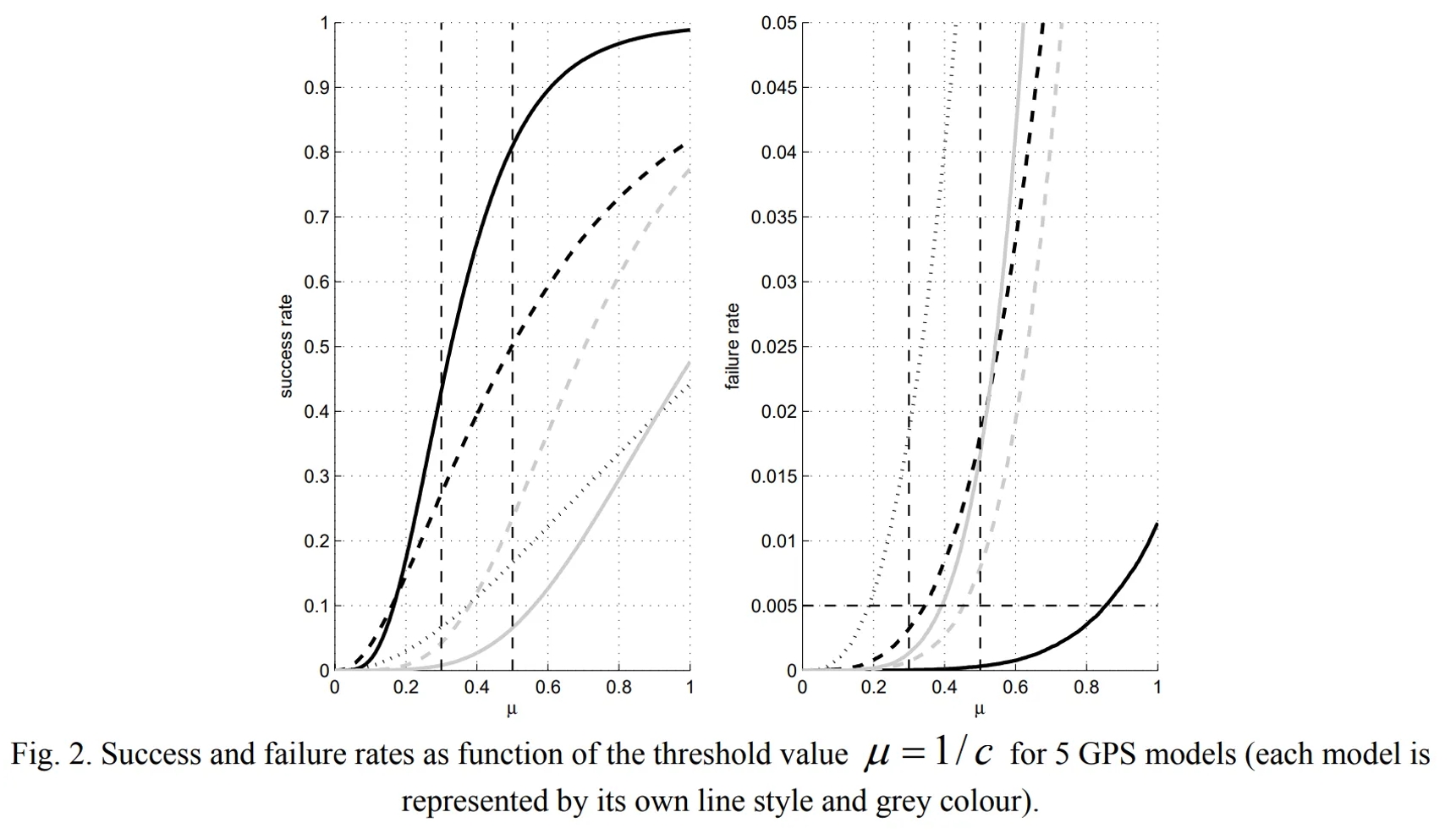
图A.9-2 成功率和失败率作为阈值 μ=1/5 的函数,针对 5 个 GPS 模型(每个模型以其独特的线条样式和灰度颜色表示)
- 解的状态。论文中包含三种状态:成功、失败(假固定)、未定(未固定),三者的概率和为1。上图表示了五种GNSS模型的成功率和失败率随着mu的的变化的示意图(说明了不同模型应该存在不同的阈值)。
- mu的含义。其中mu为1/c,而c应该是ratio-test的门限阈值。
- 失败率。从摘要来看,本文主要研究了失败率。
3. ratio-test与failure-rate的对比
1)假Fix对比
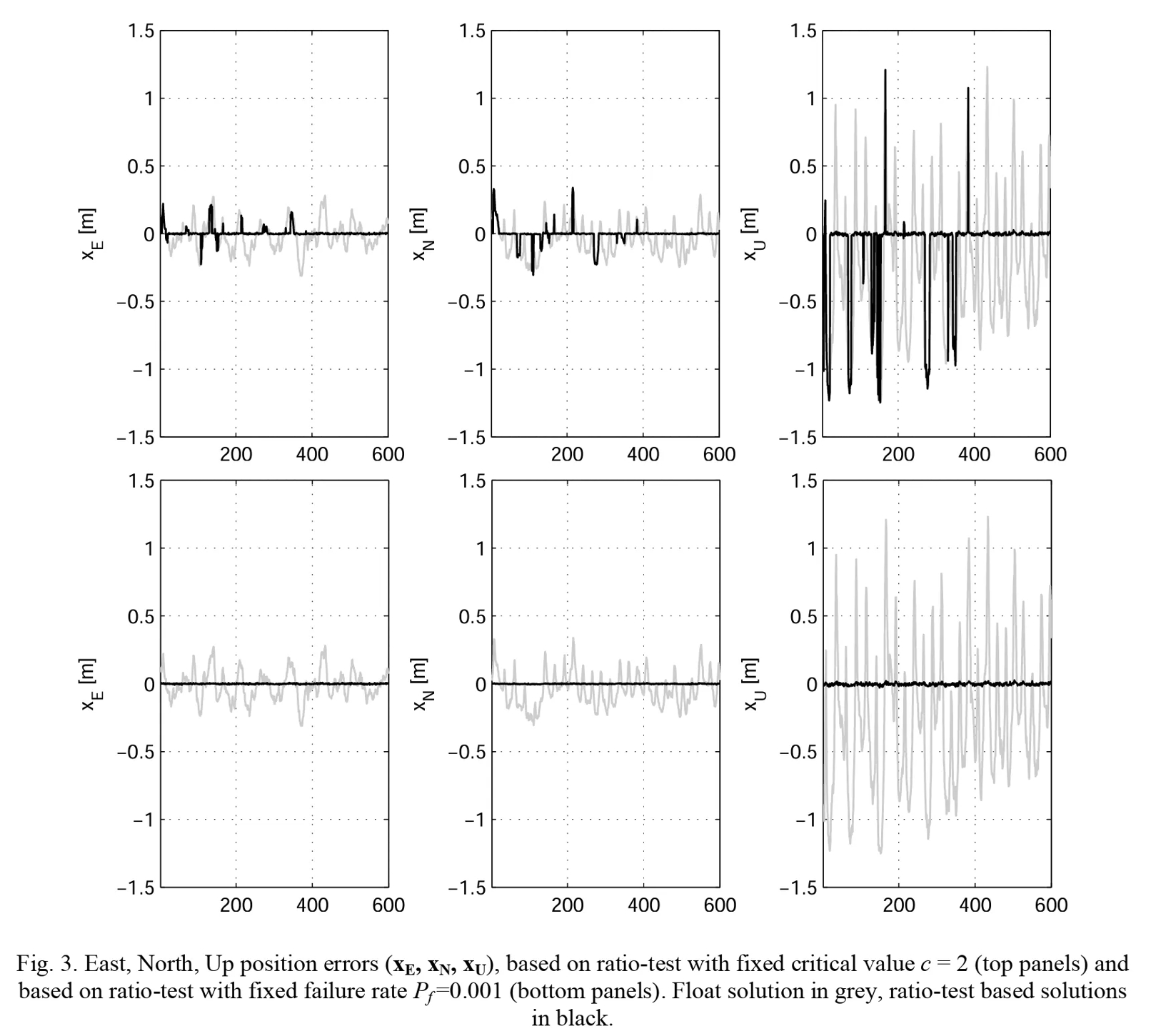
图A.9-3东西(XE)、南北(XN)、高程(XU)位置误差,基于固定临界值 c=2 的比率测试(上图)以及基于固定失败率 P=0.001 的比率测试(下图)。灰色表示浮点解,黑色表示基于比率测试的解。
图中上部分显示的ratio-test设定阈值为2时定位情况,可以看到出现了很多假Fix。图中下部分显示了failure-rate设置0.001时的效果,可以看到没有假Fix。
2)拒绝的Fix对比

图A.9-4 历元-by-历元的值 q(ă)/q(ă ')。黑色:被拒绝的样本;灰色:被接受的样本。上图:若 q(ă)/q(ă) < 1/c,其中 c=2,则接受;下图:P=0.001。
图中上部分是ratio-test,它显示了设定了固定的阈值导致很多潜在的Fix解被拒绝了。图中下部分是failure-rate则表现得更好。
3)对比的结论
表A.9-1 经验模糊度解析概率(单位:%)
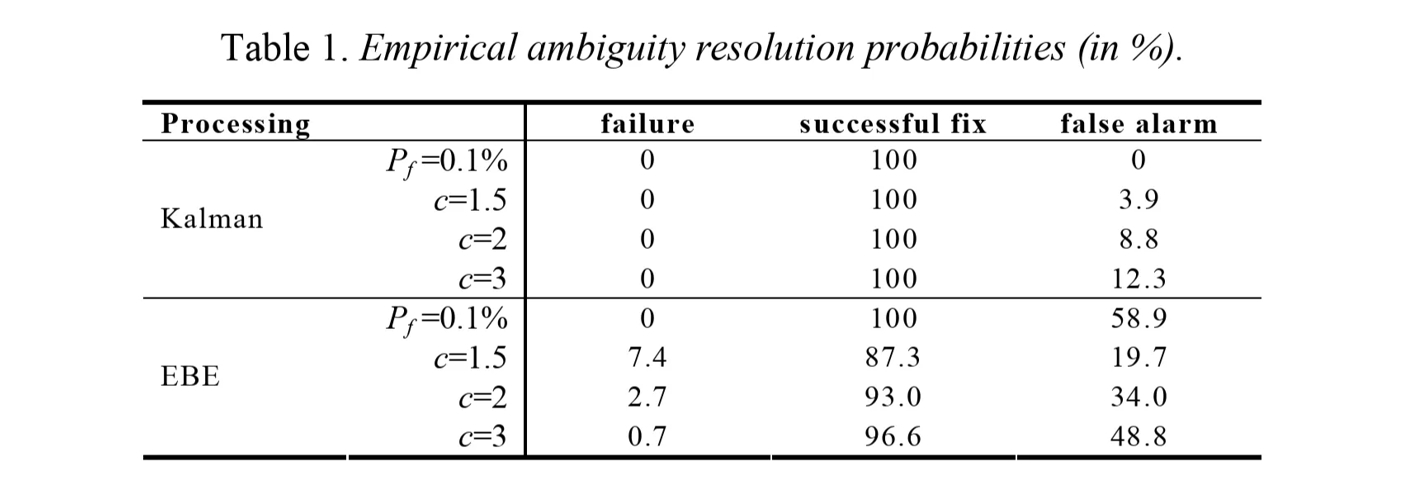
包括前面的图表,主要想表示:
- ratio-test在一些情况下会造成假Fix;
- ratio-test在一些情况下会拒绝一些真Fix;
而failure-rate可以缓解上面的问题。另外上面的EBE指的是逐历元,即假设模糊度在不同历元之间不是恒定的。而卡尔曼滤波假设模糊度恒定,位置动态。
4)其他
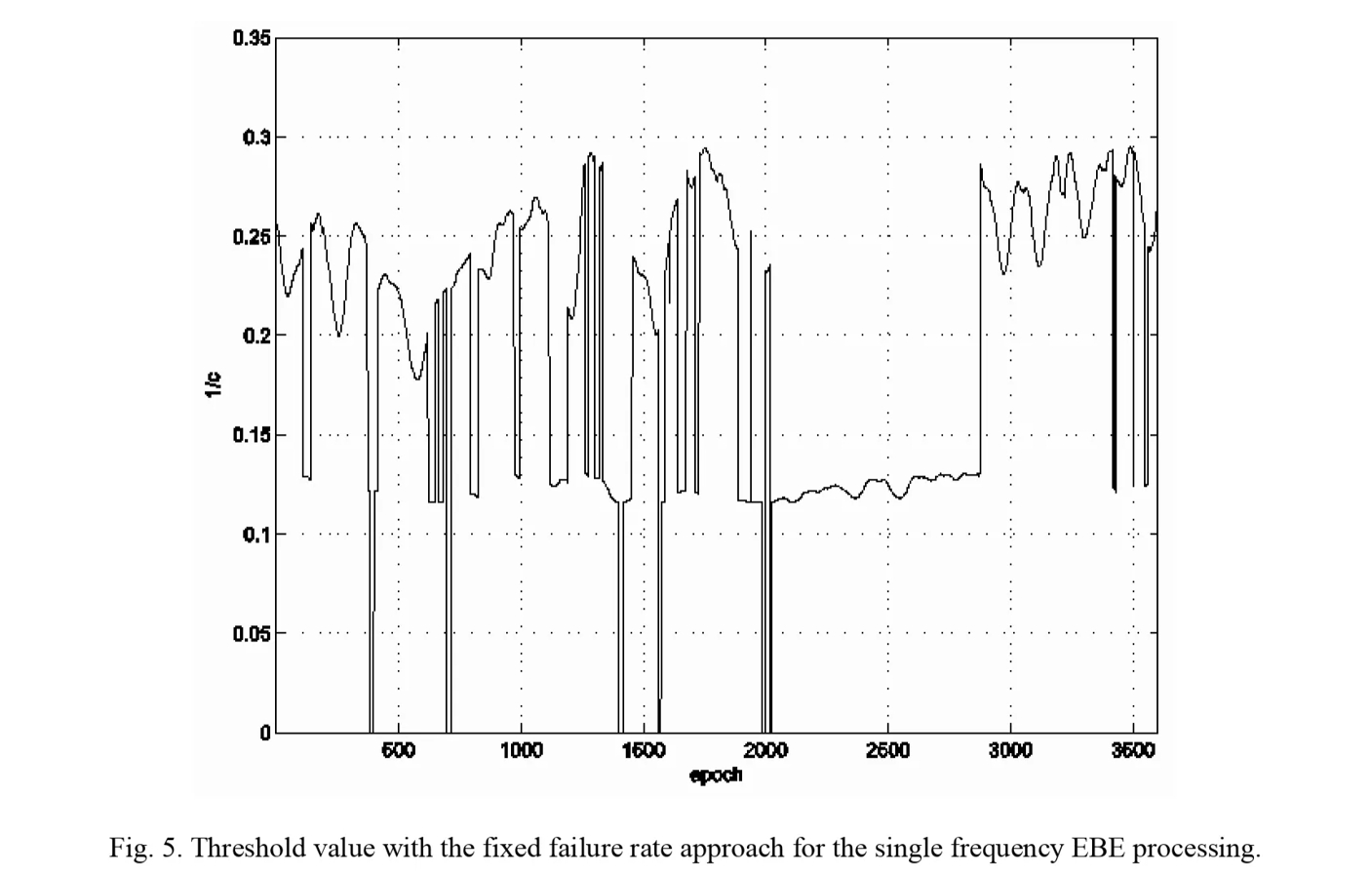
图A.9-5 固定失败率方法下单频 EBE 处理的阈值
上图展示了EBE情况下,论文中的failure-rate方法得到的逐历元1/c值。
它表明:由于底层模型的强度随着历元发生了变化,相应的c值也需要从历元到历元发生变化。而当跟踪的卫星数量减少或增加时,1/c值会出现突然变化。
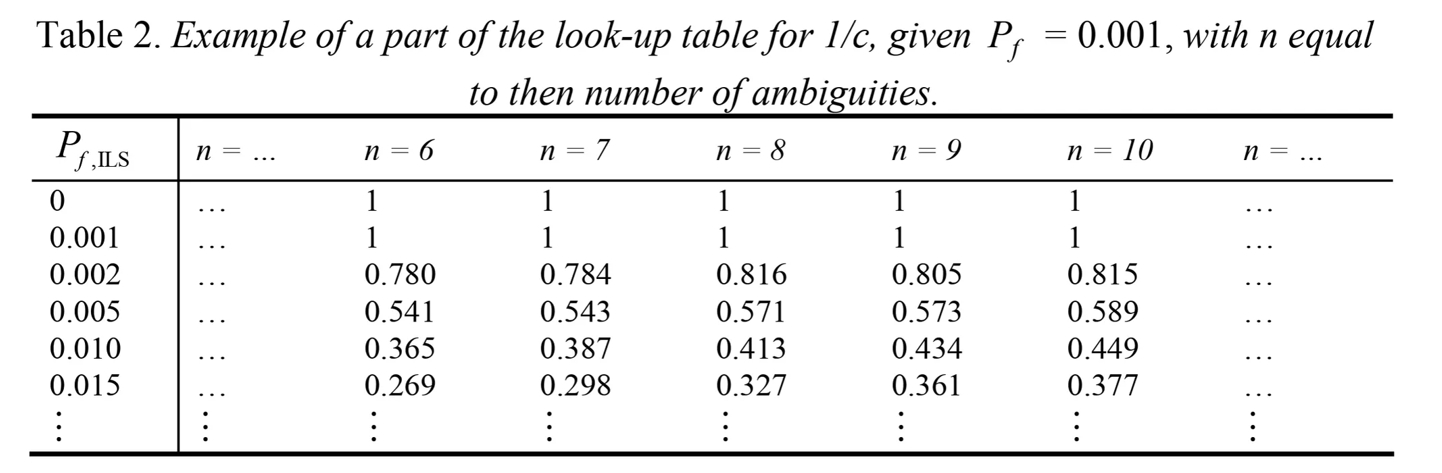
5)failure-rate确定c的查找表
表A.9-2 查找表的一部分示例,针对 1/c,其中 P = 0.001,n 等于模糊度的数量
表A.9-2 使用查找表近似阈值(黑色实线)的失败率和固定概率。还显示了真实值(黑色虚线)和固定阈值 c=2 的值(灰色)。左侧面板:3频 GPS,15 个模糊度;右侧面板:2频 Galileo/GPS,20 个模糊度
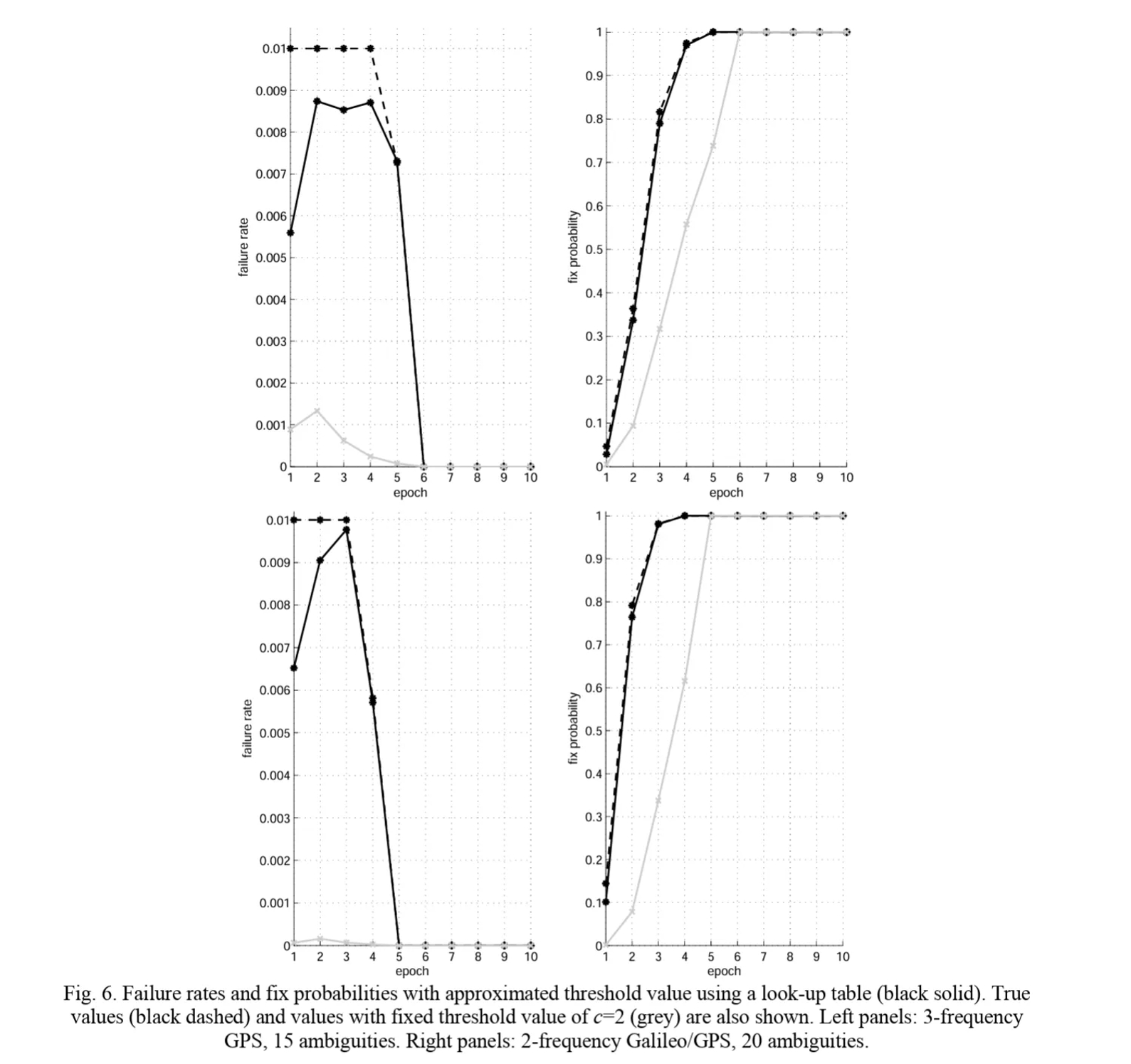
图A.9-6 使用查找表近似阈值(黑色实线)的失败率和固定概率。还显示了真实值(黑色虚线)和固定阈值 c=2 的值(灰色)。左侧面板:3频 GPS,15 个模糊度;右侧面板:2频 Galileo/GPS,20 个模糊度
- 黑色实线:根据查找表确定的失败率和固定概率;
- 黑色虚线:真实值;
- 灰色实线:固定阈值c=2时的值。
上图上半部分:三频GPS,15个模糊度。下半部分:双频Galileo/GPS,20个模糊度。
A.9.4 结论
1. ratio-test的特性
- 常见误解。它并非用于检验ILS的正确性,ratio-test的作用是为了检验浮点解与其最近的整数向量的接近程度(ratio-test无法检测浮点解中的整数偏差);
- 阈值设定。ratio-test设定固定的临界值并没有理论支持,对于不同的模型,可能需要设定不同的临界值。
2. 工程实现
失败率查找表。可以根据查找表,根据失败率计算临界值(参考demo5的实现)。
3. ratio-test与孔径估计理论
- 理论从属。比率检验是整数孔径估计理论提供的一类检验方法之一;
- 最优检验。ratio-test不是最优的,最优的检验,即在用户固定的失败率下最大化做出正确决策概率的检验。
A.10 模糊度固定原理
这里参考自网传资料,而并不知道其具体来源,因此这里并没有注明来源,如有侵权还请告知去除。该网传资料一部分内容参考了资料 [21][22]。